Knowledge
What is a Data Contract?
A data contract defines the structure, format, semantics, quality, and terms of use for exchanging data between a data provider and their consumers. A data contract is implemented by a data product’s output port or other data technologies. Data contracts can also be used for the input port to specify the expectations of data dependencies and verify given guarantees.
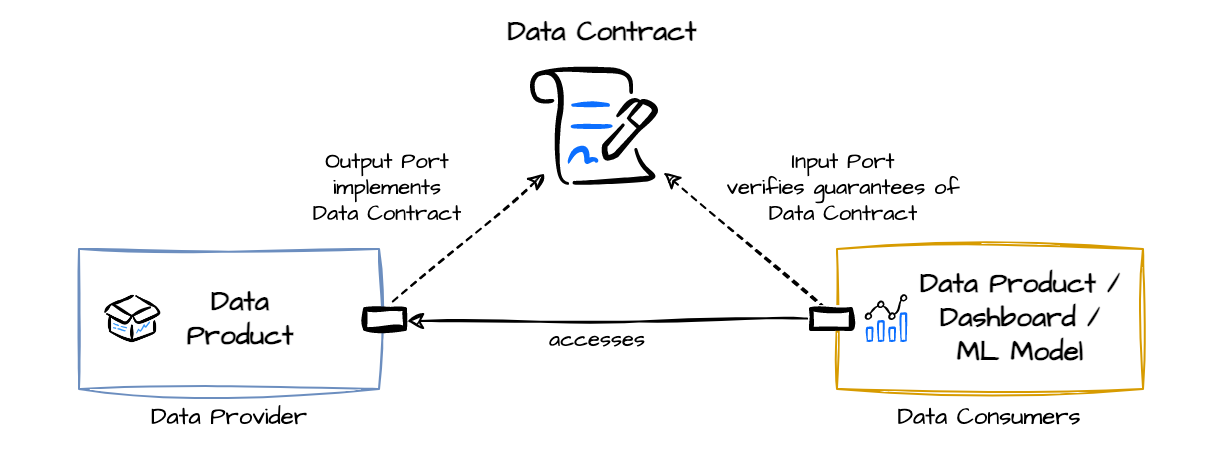
Data Contract Example
Let's start with an example to see, what a data contract typically covers:
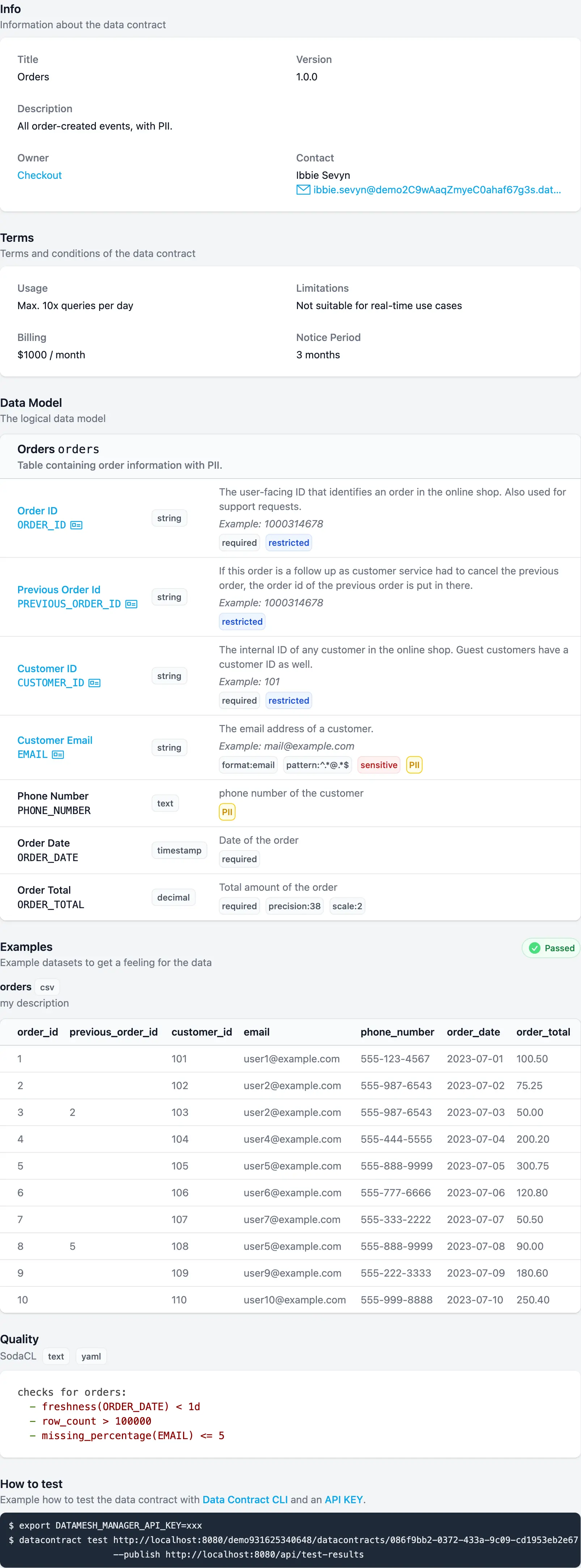
Before we dive into all the details, let's discuss, how we use data contracts.
Collaboration
Data contracts come into play when data is exchanged between different teams or organizational units, such as in a data mesh architecture. First, and foremost, data contracts are a communication tool to express a common understanding of how data should be structured and interpreted. They make semantic and quality expectations explicit. They are often created collaboratively in workshops together with data providers and data consumers, even before the data product is implemented. This is what we call contract-first. Later in development and production, they also serve as the basis for code generation, testing, schema validations, quality checks, monitoring, access control, and computational governance policies.
In a data contract, all attributes of a data model are precisely described and defined with their syntax and semantics. This can be done in the form of technology-neutral way or a technology-specific schema (e.g., SQL DDL, dbt model, Protobuf, JSON Schema), or both. These serve as fixed points for the provider team, which must always be adhered to. But it is also gives flexibility for the providing team, how to design and implement internal components of a data product to fulfill this interface. Consumers can trust that the fields are stable and meet the defined quality standards.
Approval Process
Note
The term data contract does not align with a contract in a legal sense as a mutual agreement between two parties. A data contract specifies the provided data set and is owned by one party, typically the data provider. So, the term data contract may be somewhat misleading, but it is how it is used in practice. The mutual agreement between one data provider and one data consumer is the data usage agreement that refers to a data contract.
The bilateral agreement is reached through an approval process:
A consumer team interested in using the data submits a request to access the data product of another team (provider team). It states the purpose of the intended data usage. The provider team then decides whether to approve the request, based on criteria such as the usage terms, a valid purpose, and need-to-know principle, or whether to need to negotiate anything further with the consumer team. When the request is approved, a data usage agreement is concluded with the data consumer.
A data usage agreement has a life-cycle with a start date, and it can be canceled by either party with respect to a defined notice period. This makes it possible for the provider team to evolve a data product, e.g., when a breaking change needs to be implemented and data consumers are advised to migrate to newer version of an output port within the notice period. Data consumers can also cancel a data product, e.g., when the costs don't meet the expected business value or the data quality is not sufficient. This embraces product-thinking: Data providers need to make sure that their consumers gain value by stable and high-quality data.
Automation and Contract Enforcement
The request flow and lifecycle processes should be fully implemented as a self-service, in line with the data mesh principles. This also includes processes and notifications for new requests, approvals, reassessments, and terminations.
Data contracts and data usage agreements can further act as the foundation to automate processes in the data platform and for computational governance: As soon as a data usage agreement has been approved and within the start date, permissions for the respective data product can be set up automatically in the data platform. When the agreement is terminated, the permissions are revoked.
Data contracts can also be the basis to perform automated tests and quality checks in the CI/CD pipeline or in data quality monitoring tools. For example, a regular check ensures that the schema conforms to the agreed data model and the data meets the defined quality attributes.
Data Contract Specification
For automation, a data contract must be available in a machine-readable form, such as a YAML representation. This is why we propose the Data Contract Specification:
The example from above, encoded as YAML:
dataContractSpecification: 0.9.1
id: urn:datacontract:checkout:snowflake_orders_npii_v2
info:
title: snowflake_orders_npii_v2
version: 1.0.0
description: "All order-created events, PII removed."
owner: checkout
contact: {}
terms:
usage: Max. 10x queries per day
limitations: Not suitable for real-time use cases
billing: $1000 / month
noticePeriod: P3M
models:
orders:
type: table
description: Table containing order information with masked PII.
fields:
order_id:
type: text
description: Unique identifier for the order.
customer_id:
type: text
description: Unique identifier for the customer.
email:
type: text
description: Masked email address of the customer.
phone_number:
type: text
description: Masked phone number of the customer.
order_date:
type: timestamp
description: Date of the order.
order_total:
type: decimal
description: Total amount of the order.
schema:
type: sql-ddl
specification: |-
CREATE TABLE orders (
order_id STRING COMMENT 'Unique identifier for the order.',
customer_id STRING COMMENT 'Unique identifier for the customer.',
email STRING COMMENT 'Masked email address of the customer.',
phone_number STRING COMMENT 'Masked phone number of the customer.',
order_date TIMESTAMP_TZ COMMENT 'Date of the order.',
order_total DECIMAL COMMENT 'Total amount of the order.'
);
examples:
- type: csv
description: Randomly generated values via ChatGPT
data: |-
order_id,customer_id,email,phone_number,order_date,order_total
1,101,masked_email_1,masked_phone_1,2023-07-01,100.50
2,102,masked_email_2,masked_phone_2,2023-07-02,75.25
3,103,masked_email_3,masked_phone_3,2023-07-03,50.00
4,104,masked_email_4,masked_phone_4,2023-07-04,200.20
5,105,masked_email_5,masked_phone_5,2023-07-05,300.75
6,106,masked_email_6,masked_phone_6,2023-07-06,120.80
7,107,masked_email_7,masked_phone_7,2023-07-07,50.50
8,108,masked_email_8,masked_phone_8,2023-07-08,90.00
9,109,masked_email_9,masked_phone_9,2023-07-09,180.60
10,110,masked_email_10,masked_phone_10,2023-07-10,250.40
quality:
type: custom
specification: |-
quality_checks:
- name: Check for Null Values
description: Ensure that there are no missing values in critical columns.
sql: |
SELECT *
FROM orders
WHERE order_id IS NULL
OR customer_id IS NULL
OR email IS NULL
OR phone_number IS NULL
OR order_date IS NULL
OR order_total IS NULL;
- name: Check for Duplicates
description: Ensure that each order has a unique identifier, and there are no duplicate entries in the "orders" table.
sql: |
SELECT order_id
FROM orders
GROUP BY order_id
HAVING COUNT(*) > 1;
- name: Check for Valid Email Addresses
description: Ensure that the "email" column contains valid email addresses using a standard email pattern.
sql: |
SELECT *
FROM orders
WHERE NOT REGEXP_LIKE(email, '[A-Za-z0-9._%+-]+@[A-Za-z0-9.-]+\.[A-Z|a-z]{2,}');
- name: Check for Positive Order Total
description: Ensure that the "order_total" column contains positive values, indicating valid order amounts.
sql: |
SELECT *
FROM orders
WHERE order_total < 0;
- name: Check Order Date Within a Reasonable Range
description: Ensure that the "order_date" falls within the range from January 1, 2020, to December 31, 2023, to verify the dates are within a reasonable timeframe.
sql: |
SELECT *
FROM orders
WHERE order_date < '2020-01-01' OR order_date > '2023-12-31';
The example follows the Data Contract Specification that is compatible with Data Mesh Manager's Data Contract API.
The YAML can be read by tools, such as the Data Contract CLI to automate code generation, detect breaking changes in the CI/CD pipeline and to trigger other tools, such as Soda Core Engine to validate quality attributes on the actual data sets.
Visualize the Data Mesh
Data contracts and data usage agreements are also powerful for data discovery and data lineage. You can think of a data mesh architecture as a graph: Data products are the nodes, and data usage agreements represent the edges between data products. With that, the data mesh can be visualized as a map:
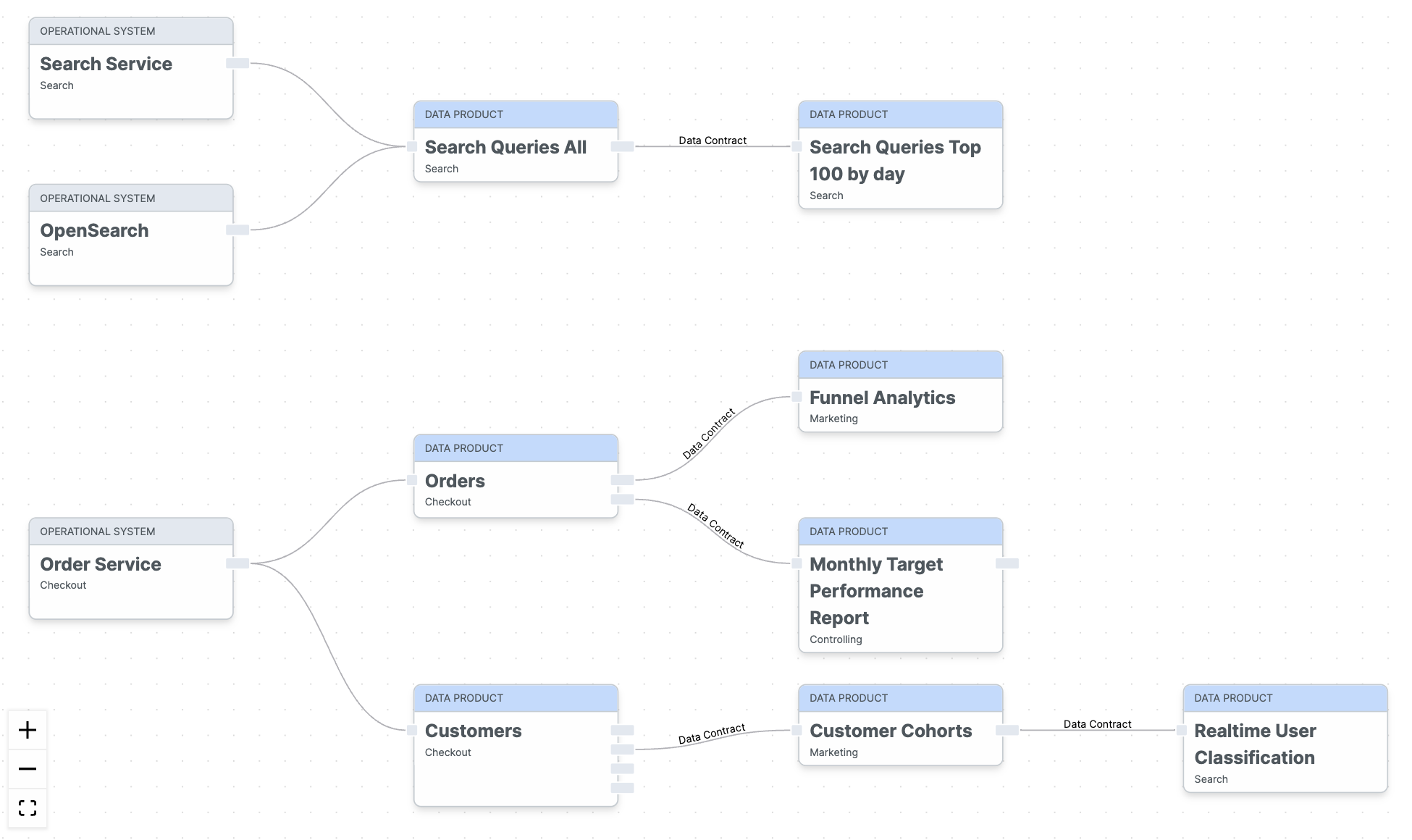
Such a data map is a way of making the use of data in the company comprehensible and traceable across teams and domains.
Data Mesh Manager
Data contracts need to be managed efficiently and comprehensibly. Many of our customers used a wiki for this purpose, but this quickly reaches its limits and enables hardly any automation.
Since there was no other good tool available for managing data contracts and data usage agreements, we developed Data Mesh Manager, to manage data products, data contracts, and global policies as a web-based self-service. An event-based API enables seamless integration with any data platform. And any change will be recorded in an audit trail.
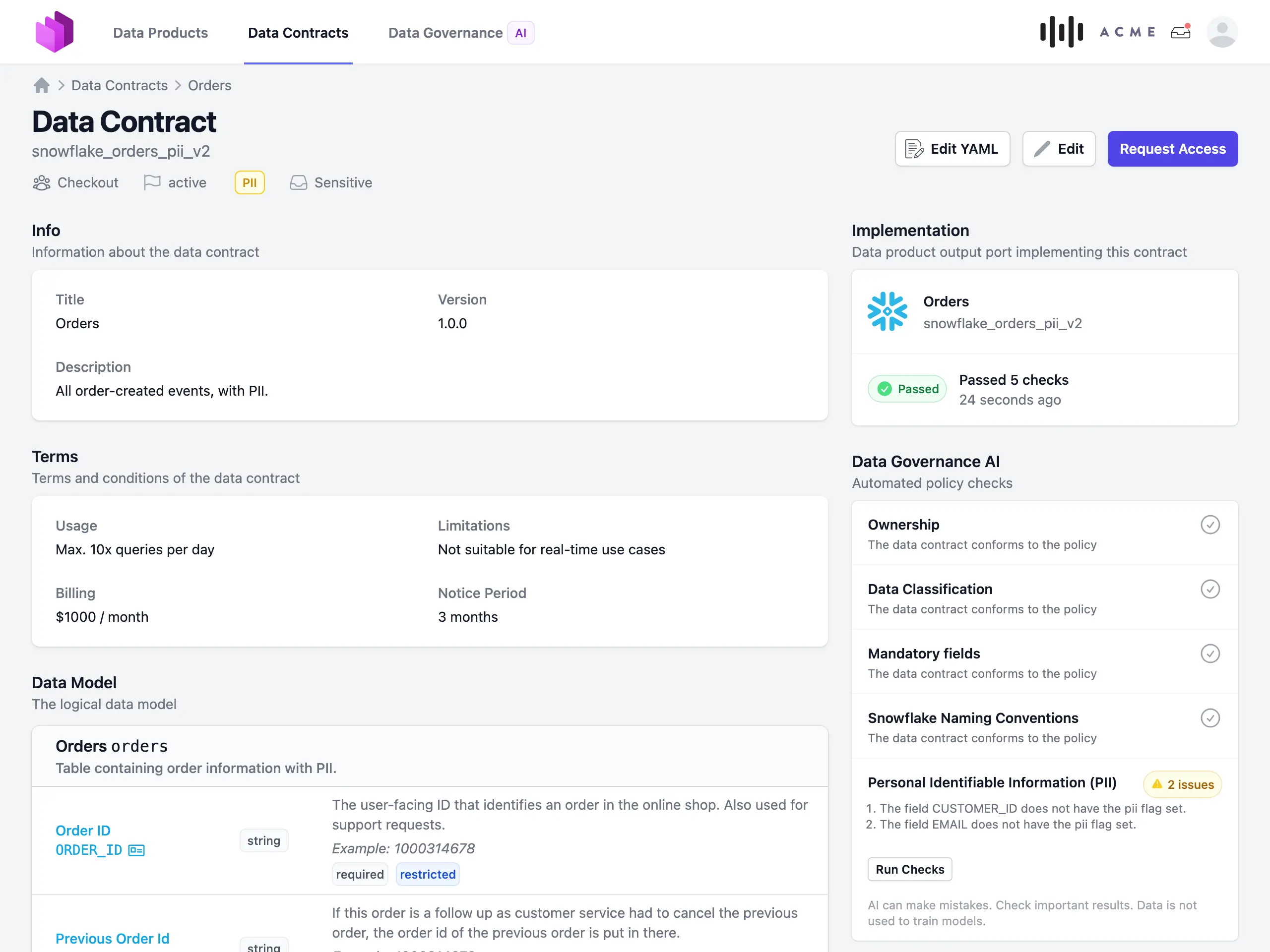
In addition to a data product inventory for finding and evaluating data products, the Data Mesh Manager also supports a request and accept flow for creating data usage agreements, as well as an event-based API for automatically creating and revoking permissions in the data platform. The visualization as a data map makes the mesh comprehensive and the use of the data products traceable.
Sign up now for free, or explore the clickable demo of Data Mesh Manager.